Multimodal
Generative AI has been dominated by single-modal conversions, such as text-to-image and image-to-text. In recent years, research and development of technologies that comprehensively handle multimodal input, including images, text, and voice, has progressed. This evolution of multimodal AI makes it possible to handle information in a multifaceted, intuitive, and high-resolution manner by connecting media and people, and even between media. We aim to utilize this technology to create new services that are even more convenient and useful than conventional services.
-
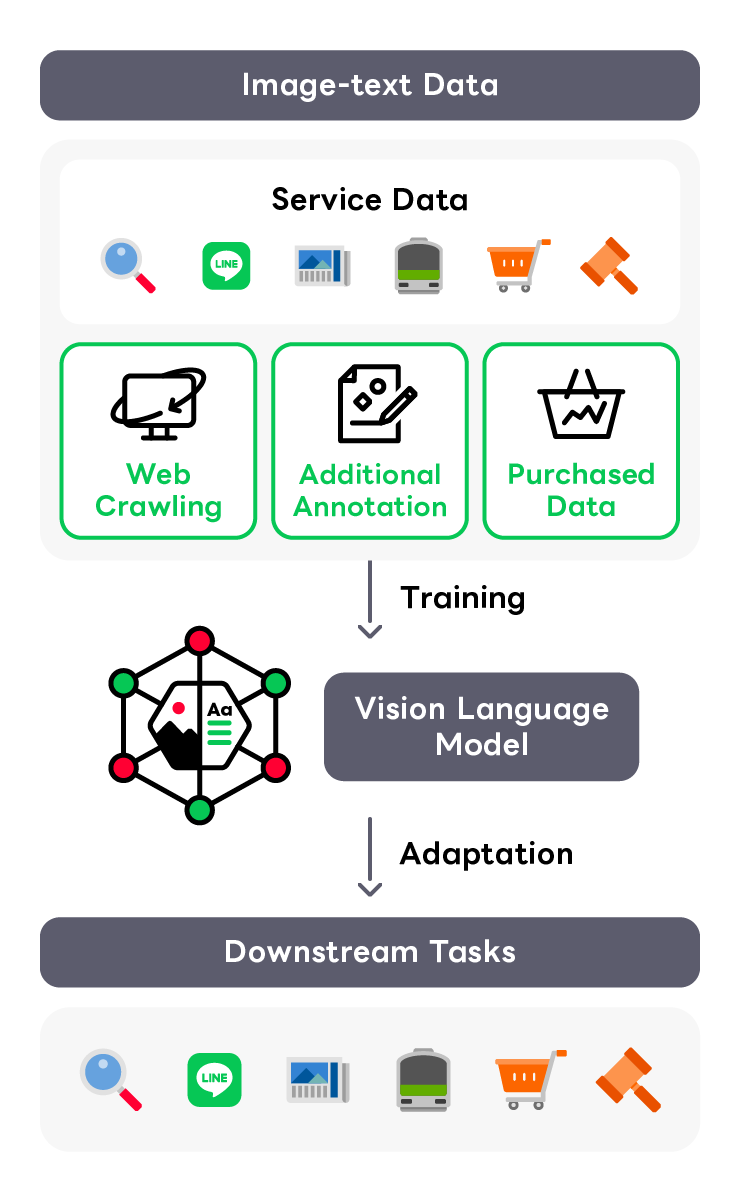
Vision & Language
Image processing technology is utilized throughout our services, however, there are still numerous tasks that remain unaddressed due to the labor involved in model development and the difficulty of data collection. To address these issues, research on large-scale Vision Language Models (VLM) is being conducted across various companies and research institutions. We are also advancing the development of a proprietary Japanese VLM using abundant computational resources, the diverse data from our services and high-quality data collected independently.
-
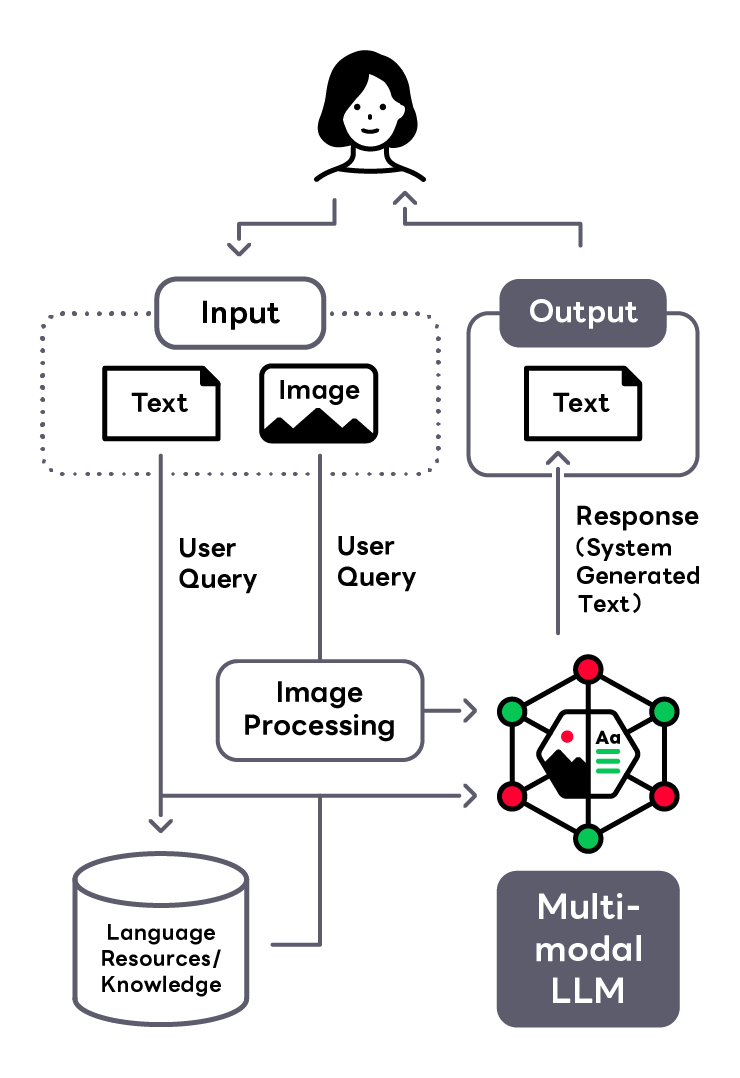
Visual Talk
Visual Talk demonstrates the prototype of AI communication to human with images and texts based on Generative-AI technology. This demonstration has been implemented of two main systems; (i) One is the analyzing system for image and text inputs from the human. (ii) Another is the generating system to response AI's message to human by a multimodal large-scale language model based on the analyzed contents. Visual Talk is being researched as one of the prototype with multimodal technologies combining Computer Vision and Natural Language Processing (NLP). We expect these multimodal technologies with Generative AI to apply into various web services, such as AI assistants for e-commerce services and improving the user's experience of search services in the future.
-
Human Motion Analysis
Many machine learning tasks involve modeling and analyzing human behavior, and understanding human actions is a key component to solving these tasks. Analyzing human motion plays an important part in various tasks, from human motion classification to novel human motion generation. However, diversity among different human beings induce randomness to different actions and behaviors, making analysis of such data difficult. We focus on capturing only the skeletal information of the human movements, and attempt to analyze human motion from various perspectives. We aim to utilize results from such analysis in various applications, including animating virtual non-existent characters.

-
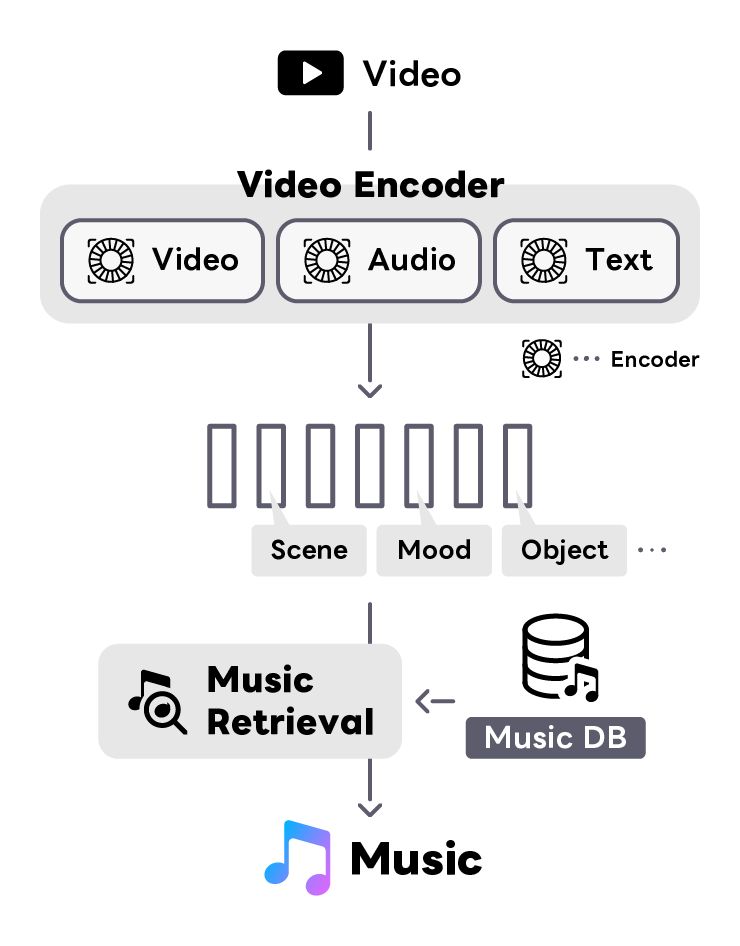
Video-to-Music Retrieval
We are conducting research and development on music recommendation technology for videos to revolutionize music selection process in video content production. The task of choosing suitable music from a library of tens of millions of songs is time-consuming when done manually and poses the challenge of valuable music being overlooked. We are creating a multimodal space that connects the audio-visual elements of a video—such as color, movement, scenes, environmental sounds—with the acoustic properties of the music, including rhythm, tonality, and emotional expression, to efficiently search for the optimal music for a video. Furthermore, we’re leveraging natural language processing technology to integrate information across modalities, aiming to realize a recommendation system with transparency and interpretability, so users can intuitively understand and trust the rationale behind the chosen music.
-
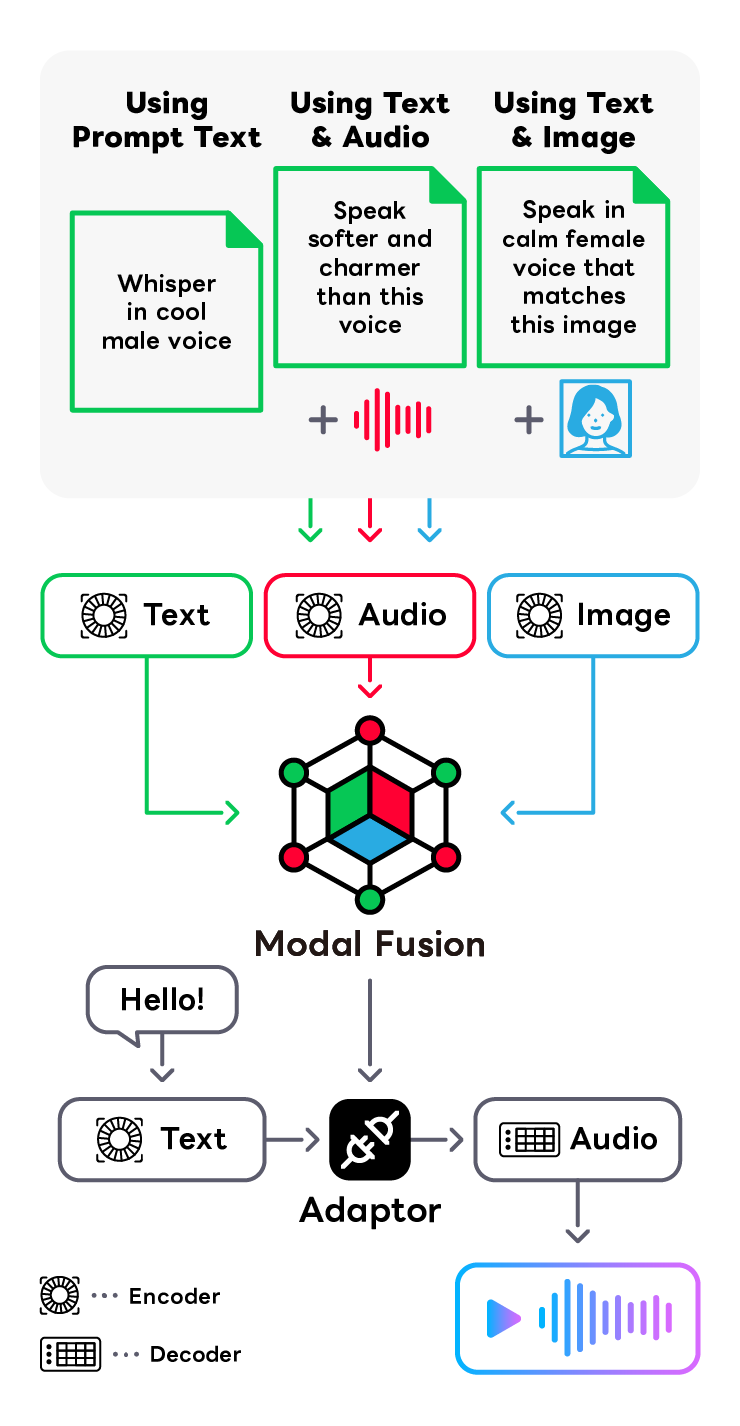
Prompt Text-to-speech
In the practical application of speech synthesis, there is a need for mechanisms that can deliver voice quality and speaking styles tailored to specific uses with a high degree of control. Traditional control methods, which involve individually manipulating parameters such as speaker identity, speaking style, and pitch, have been the mainstream approach. However, these methods come with challenges in control complexity. To solve this problem, we are conducting research and development on speech synthesis that can control voice quality and speaking style based on minimal user instructions through prompts. By integrating multimodal models capable of understanding speech, language, and images, we aim to establish an intuitive and simple prompt control technology.