マルチモーダル
生成AIはこれまでテキストから画像、画像からテキストといったシングルモーダル変換が主流でしたが、近年では画像・テキスト・音声など、マルチモーダル入力を総合的に扱う技術へと研究開発が進んでいます。 このようなマルチモーダルAIの進化により、メディアと人、さらにはメディア同士をつなぐことで、情報を多角的かつ直感的に、そして高解像度で扱うことが可能になります。 LINEヤフーは、この技術を活用して、従来のサービスよりも一層利便性と有用性に優れた新たなサービスを創造することを目指しています。
-
Vision & Language
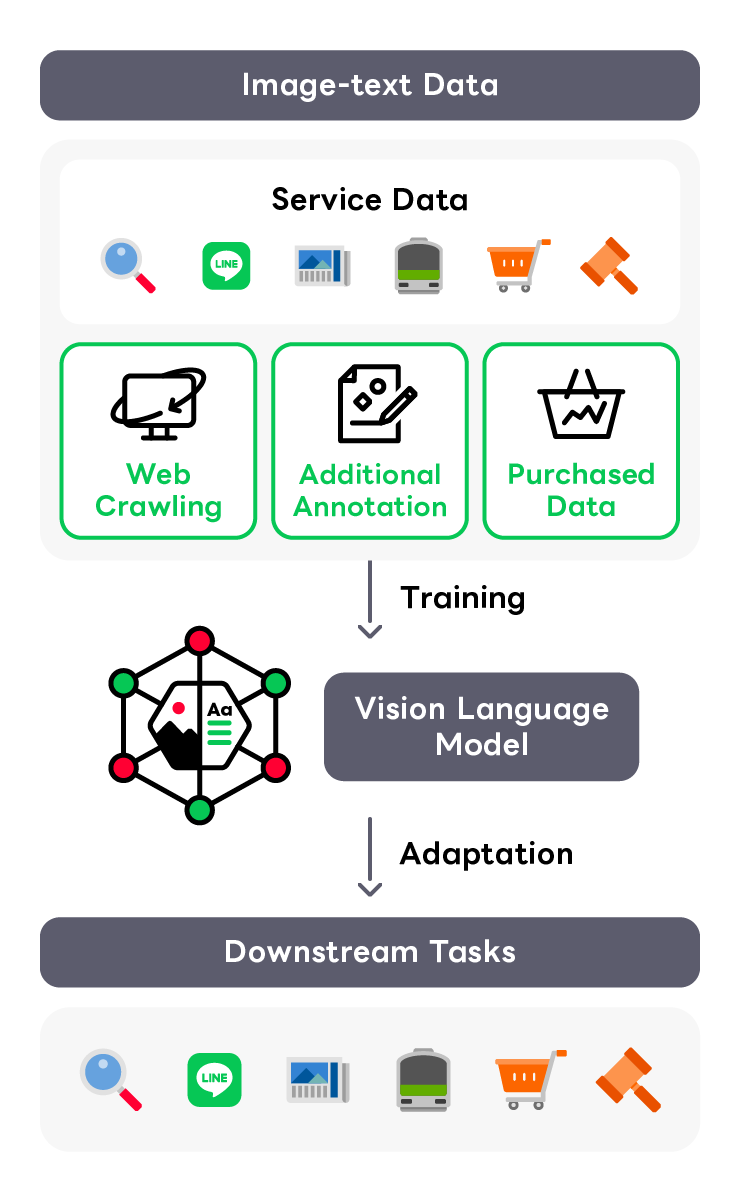
社内サービスの至る所で画像処理技術は活用されていますが、モデル開発の手間やデータ収集の難しさから対応できていないタスクも数多くあります。 こういった課題への対応するために、さまざまな機関で大規模なText-Imageデータを使用したVision Language Model(VLM)の研究が盛んに行われています。 LINEヤフー社でも、保有する豊富な計算資源と、多岐にわたる社内サービスのデータ、独自に収集した高品質なデータを活用し、独自の日本語VLMの開発プロジェクトが進行中です。
-
Visual Talk
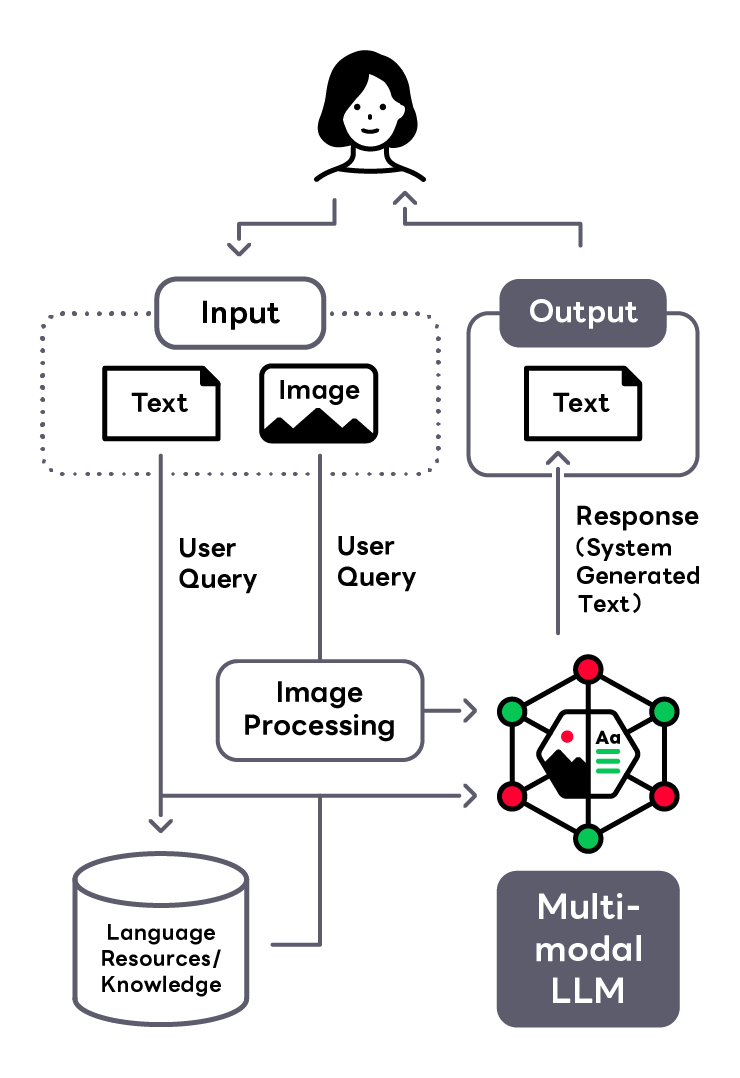
Visual Talkは、生成AI技術を用いた画像とテキストによるAIコミュニケーション技術で、コンピュータービジョンと自然言語処理(NLP)との組み合わせによるマルチモーダル技術のデモンストレーションとして研究開発されています。 Visual Talkは、ユーザーからの画像とテキストの入力に対して、マルチモーダルな大規模言語モデルによる解析と解析内容に基づく応答文の生成を行い、ユーザーとのコミュニケーションを実現します。 このようなマルチモーダルな生成AI技術は、EコマースサービスのAIアシスタントやユーザーの検索体験向上などへのさまざまなウェブサービスへの応用が期待されています.
-
Human Motion Analysis
今日の多くの機械学習の課題は人間の行動を解析しモデル化することに焦点を置かれており、これを行うためには人間の行動を理解することが重要になっている。 人間の行動解析は行動の分類から新たな行動生成まで幅広い応用先で重要な役割を担っている。 しかしながら、個性が個人によって異なるさまざまな人間の行動データの理解はとても困難な課題となっている。 弊社では、人間の行動時の骨格データに着目し、さまざまな視点から人間の行動解析を実施しており、実在しないバーチャルキャラクターへの動作付与など、幅広いアプリケーションでの応用を目指している。

-
Video-to-Music Retrieval
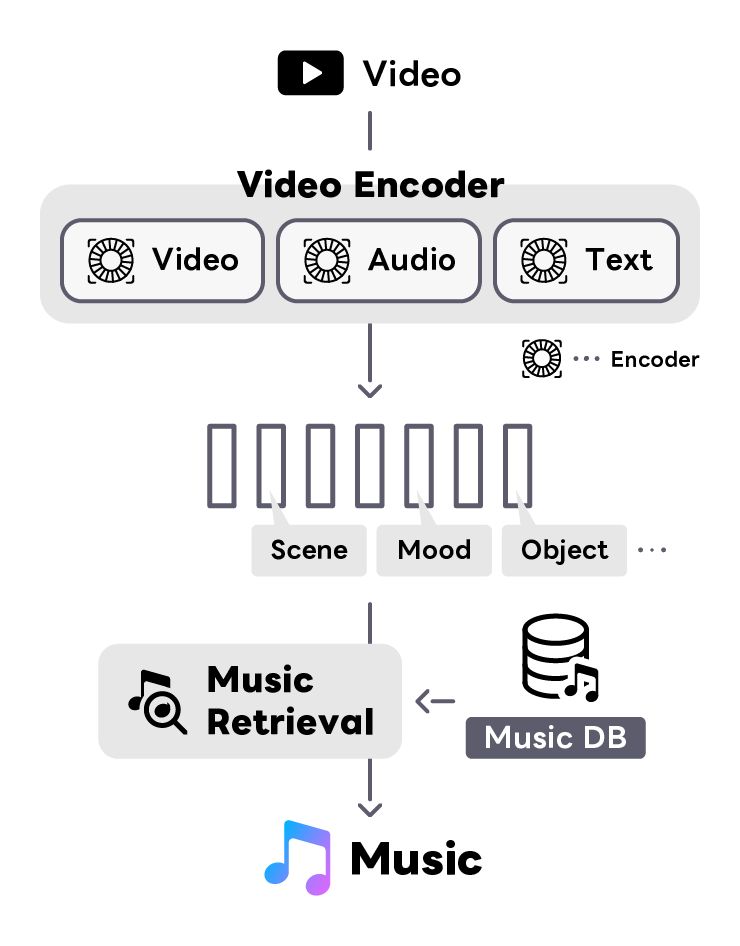
動画コンテンツ制作における音楽選定プロセスの革新のため、動画に対する音楽推薦技術の研究開発を行っています。 動画に適した音楽を数千万曲を超える音楽ライブラリから選び出す作業は、人力では膨大な時間が必要であり、価値ある音楽が埋もれてしまうという課題があります。 LINEヤフーでは、動画の色彩、動き、シーン、環境音といった視聴覚的要素と、音楽のリズム、調性、感情表現などの音響特性を結びつけたマルチモーダル空間を構築し、動画に最適な音楽を効率的に検索できる技術を開発しています。 さらに、自然言語処理技術を駆使して各モーダルの情報を統合し、ユーザーが検索音楽の選定理由を直感的に理解し信頼できるような、透明性と解釈性を備えた推薦システムの実現を目指しています。
-
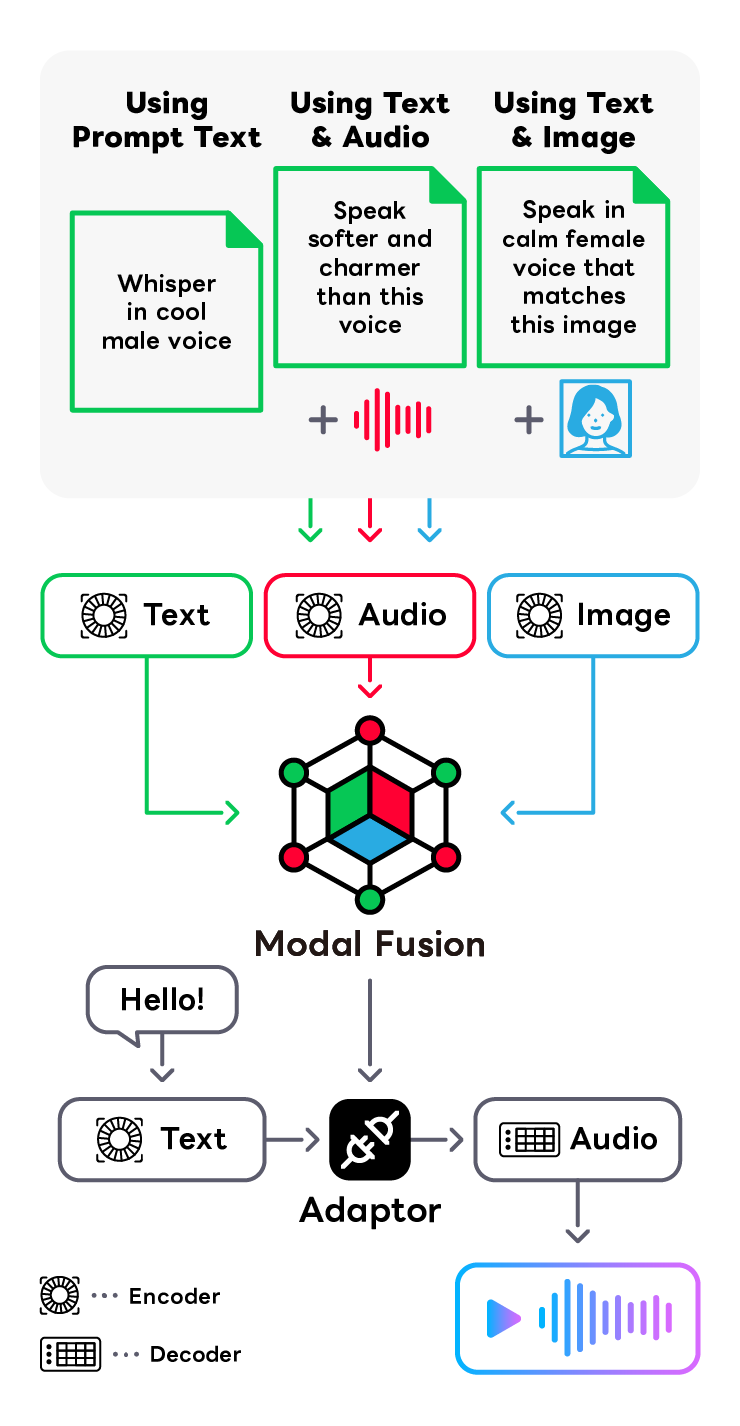
Prompt Text-to-speech
音声合成の実応用においては、用途に応じた声質や発話スタイルを実現するために、制御性の高い音声合成の仕組みが求められています。 従来の制御方式は、話者、発話スタイル、ピッチなどのパラメータを個別に制御する方法が主流ですが、この方法は制御が難しい問題があります。 LINEヤフーはこの問題を解決するために、プロンプトによるごく少量のユーザー指示を元に、声質や発話スタイルを制御可能な音声合成の研究開発をしています。 音声、言語、画像を理解可能なマルチモーダルモデルを組み込むことで、直感的で簡単なプロンプト制御技術の確立を目指します。