Speech Processing
LY Corporation is conducting research and development, aiming to create novel value to our services through advanced voice user interface and acoustic analysis of music and video data. In the area of Voice UI, we've been developing speech recognition and synthesis technologies to enhance user experiences, mainly in the search and navigation functions of our services. In the area of acoustic analysis of music and video data, we are developing a wide range of service functions, such as music recommendation systems and fraud detection in User-Generated Content (UGC) video, to improve operational efficiency.
Keyword: SpeechRecognition, SpeechSynthesis, VoiceConversion, MusicProcessing
-
High-performance Speech Recognition for Search Domain
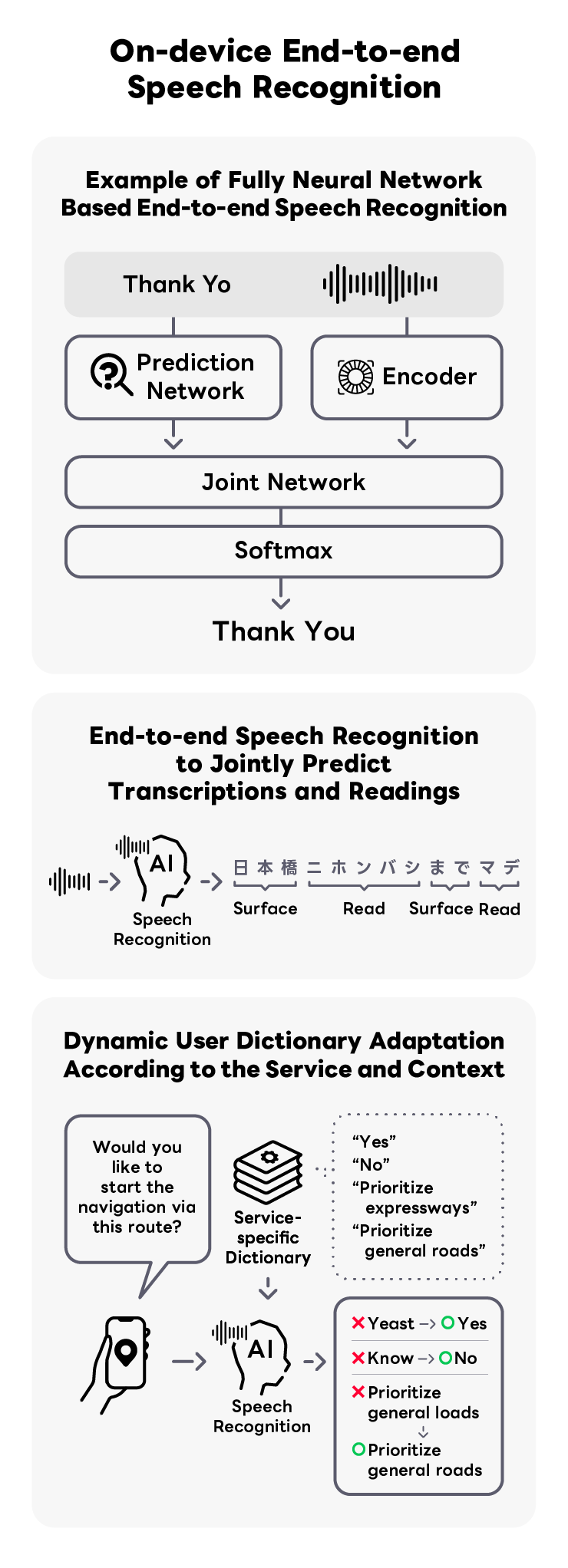
LY Corporation has implemented its own developed speech recognition technology for voice search and spoken dialogue, primarily in web searches and a wide range of vertical searches (such as maps, transit information, car navigation, etc.). The feature of our speech recognition is its high accuracy in the search domain, since it has been trained on a vast amount of web search data. In recent years, we has focused on research and development of on-device End-to-End speech recognition technology to ensure users can use speech recognition safely and securely. They have achieved products that, while being lightweight, operate with high accuracy and speed and come equipped with features that can resolve homophones unique to the Japanese language.
-
Audio Analysis Platform for Subtitling Video Content and Detecting Fraud
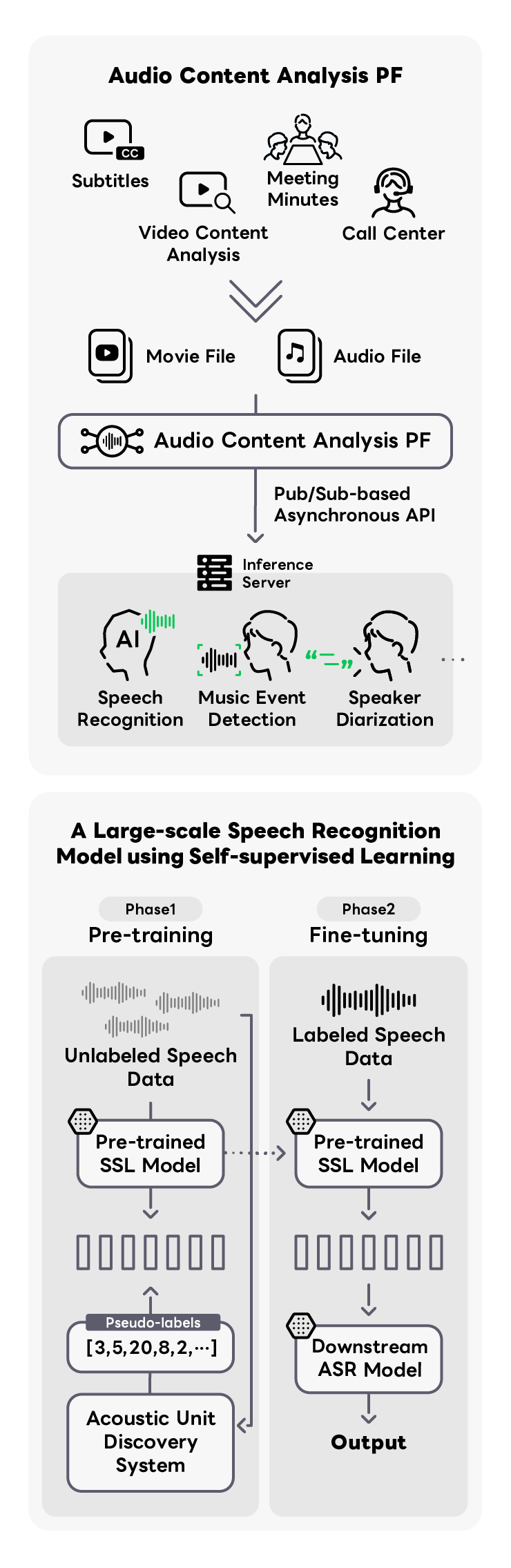
Our product supplies an integrated foundation for various audio analysis technologies, addressing a wide array of challenges, such as video captioning and fraud detection. These challenges have become increasingly prevalent with the proliferation of the video social networking market and the expansion of online meetings. We are also proactively engaged in research and development, particularly with automatic closed captioning where we utilize large-scale, end-to-end speech recognition models that leverage Self Supervised Learning (SSL). By fine-tuning these models with a dataset consolidated from LY Corporation's business portfolio, we are able to achieve highly accurate speech recognition.
-
Chat-based Music Recommendation System
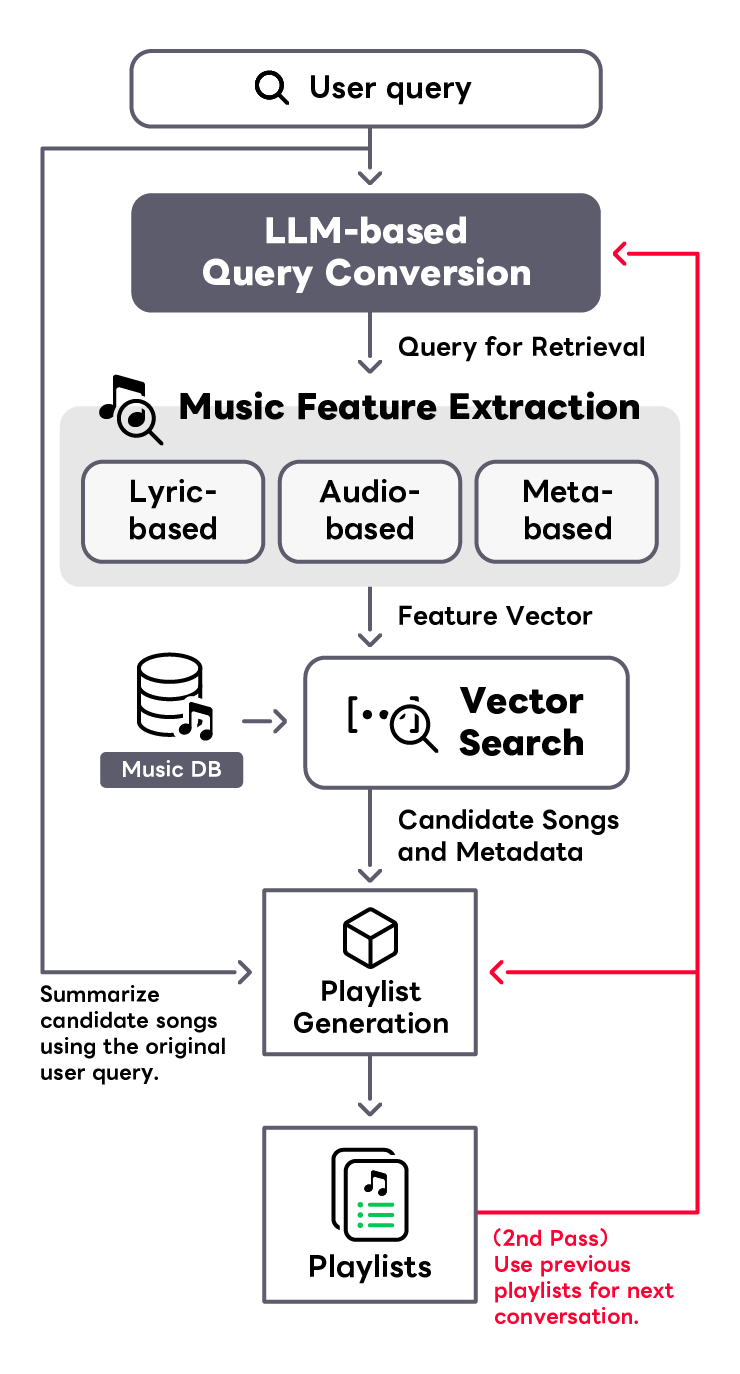
We are developing a system that allows music novices to effortlessly discover tracks that resonate with their tastes and circumstances through a conversational interface. This system deciphers abstract queries such as a user's current mood or preferred listening context using a Large Language Model (LLM), translating the results into vector embeddings. These embeddings are then used to generate music playlists via a Retrieval-augmented Generation (RAG) framework, which performs vector-based searches within a sizable music database. Our vector search component advances search technologies that encompass various characteristics of music, such as Text-to-Music Retrieval based on acoustic properties, Lyric-to-Music Retrieval that leverages the semantic content of lyrics, and Metadata-based Retrieval grounded in metadata information. These technologies are integrated to perform music searches. Our aim is to convert users' broad requests into precise music selections, curate personalized playlists, and provide a unique music discovery experience.
-
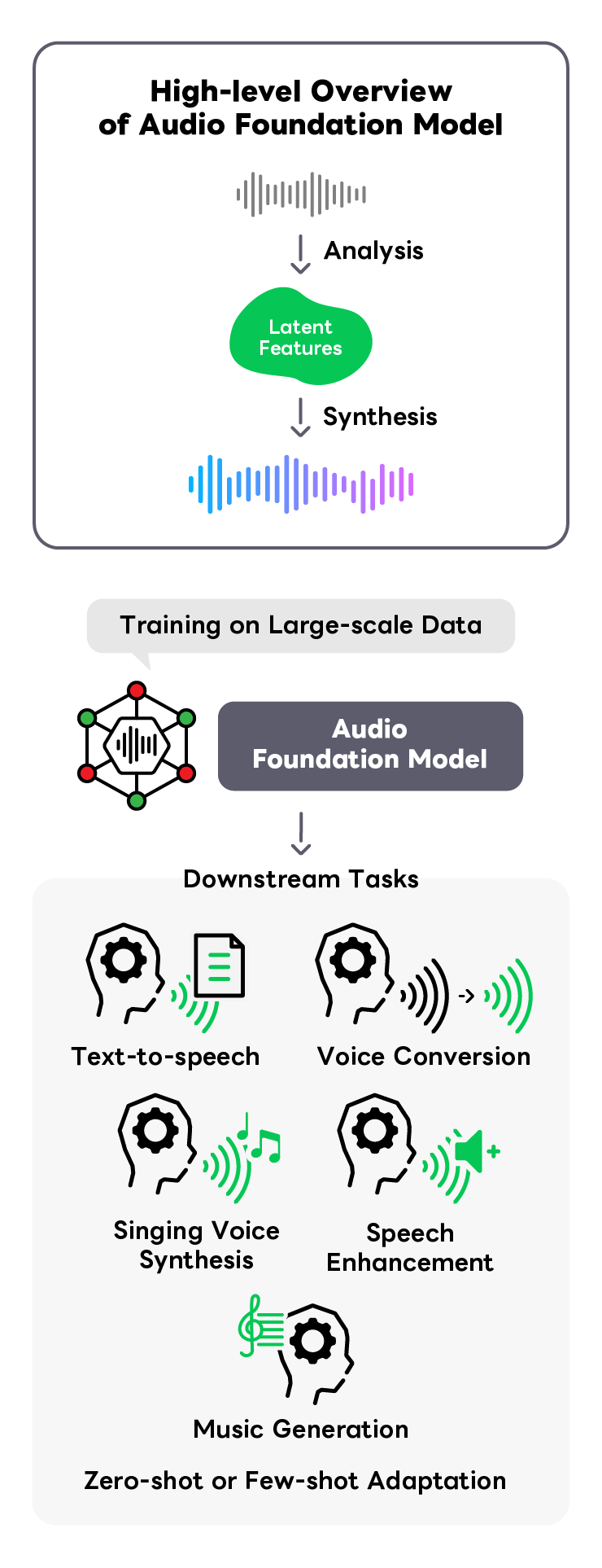
Audio Foundation Model
Various audio tasks such as speech synthesis, voice conversion, and speech enhancement have typically been addressed using specialized machine learning models dedicated to each task. However, these specialized models lack versatility and have limited potential for broader applications. We conduct cutting-edge research on speech foundational models that leverage large-scale audio data to create a more universally applicable system. By learning general-purpose latent representations of speech from data, we can solve different downstream tasks in a data-efficient manner. We conduct research on multiple perspectives, including enhancing foundational model performance, integrating with multimodal foundational models, and developing models specialized for downstream tasks.