音声処理
LINEヤフーでは、先進的な音声UIや音楽・動画データの音響解析によるサービスの新たな価値創出を目指した研究開発をしています。 音声インターフェースの分野では、音声認識・音声合成などの技術開発を通じて、サービスの検索やナビ機能を中心に高品質なユーザー体験を実現しています。 また、音楽・動画データの音響解析では、音楽推薦システムやUGC動画の不正検出などのサービス機能の開発から業務効率化まで多岐にわたる開発を推進しています。
研究キーワード: 音声認識、音声合成、音声変換、音楽情報処理
-
検索領域に高精度な音声認識技術
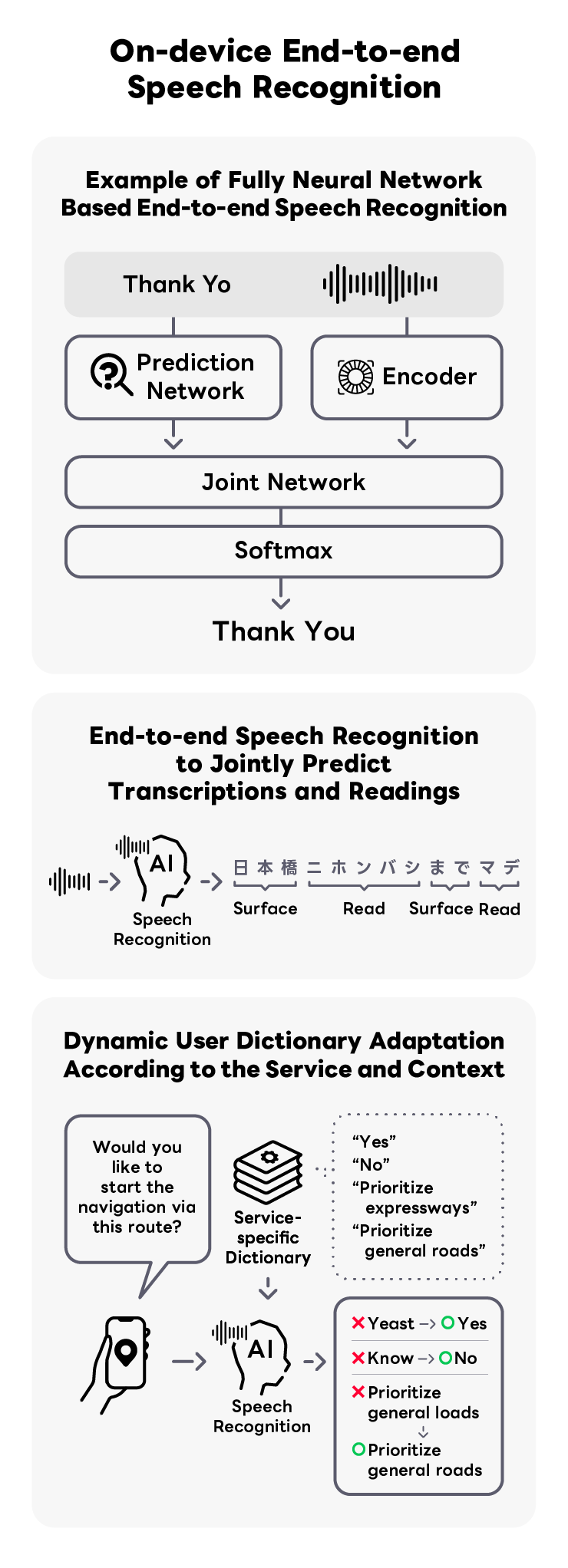
LINEヤフーでは音声認識技術を音声検索・音声対話向けに、ウェブ検索のほか、地図・乗換案内・カーナビ等の多様なバーティカル検索にも導入しています。 大規模なウェブ検索データから学習されているため、検索領域に高精度であることがLINEヤフーの音声認識の特徴です。 近年は安心・安全に音声認識をご利用していただくために、オンデバイス型End-to-End型音声認識の研究開発に注力しており、 軽量モデルでありながら高精度かつ高速に動作し、日本語独自の同音異義語も解消するなどの機能性も備えたプロダクトを実現をしています。
-
動画コンテンツの字幕付や不正検知に向けた音声解析基盤
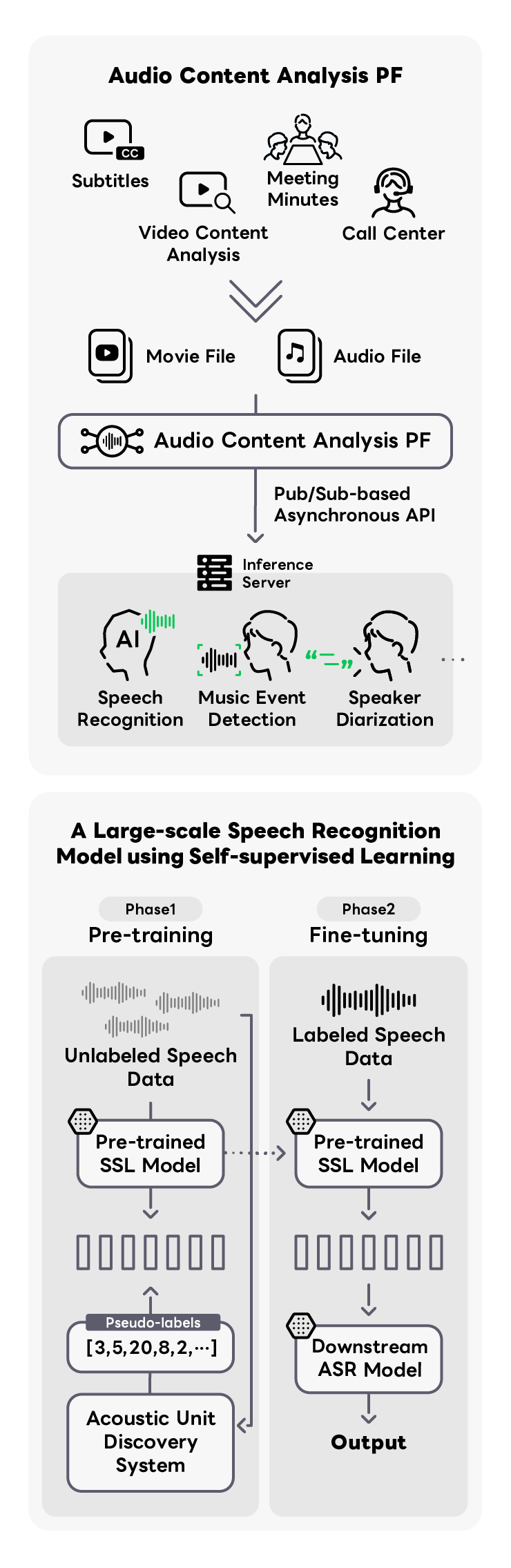
動画SNSの市場成長やオンライン会議の普及に伴う、動画字幕付や不正検出などの多種多様な課題解決をするために、 さまざまな音声解析技術を統合化した基盤技術の提供および、研究開発を行っています。 特に自動字幕付では、自己教師あり学習(Self Supervised Learning : SSL)を活用した大規模End-to-End音声認識モデルの利用しており、 LINEヤフー事業合わせたデータにチューニングをすることで高精度な音声認識を実現しています。
-
対話型音楽推薦システム
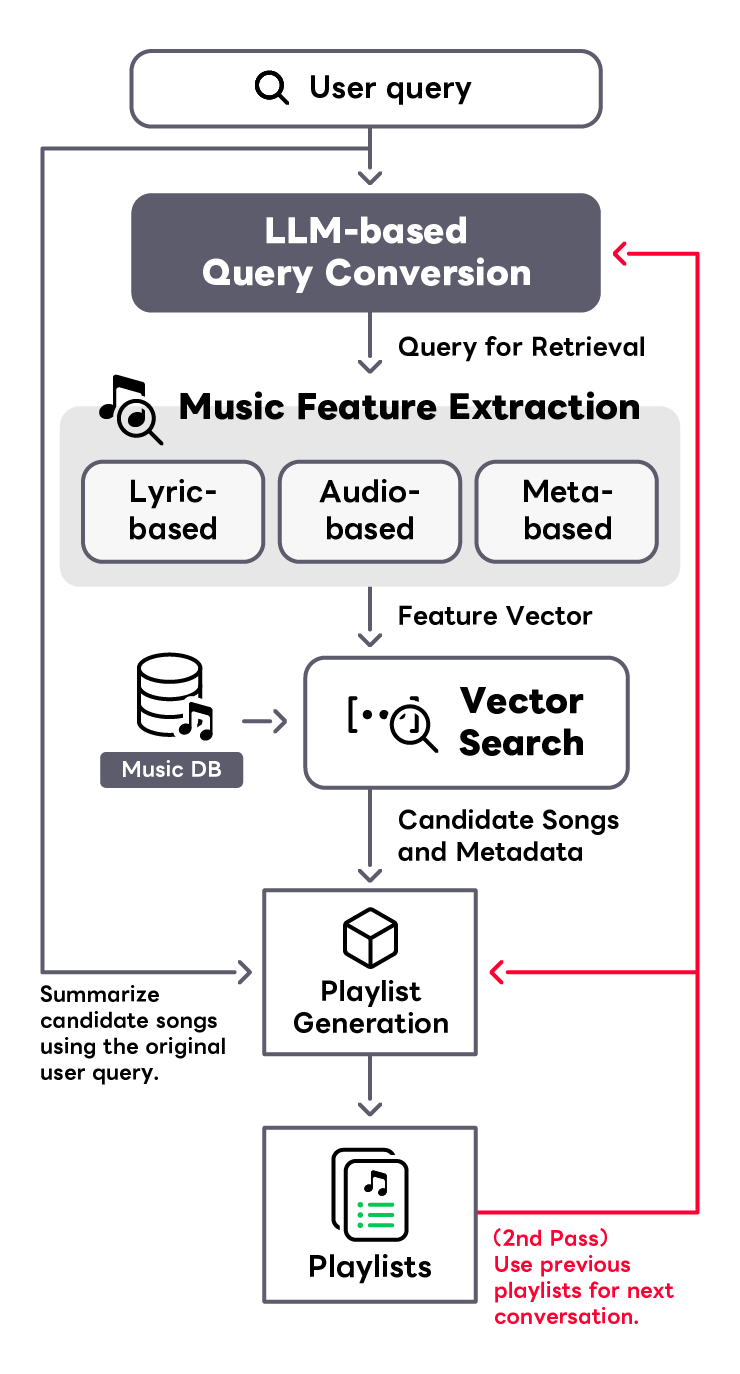
音楽の専門知識がないユーザーでも、対話型インターフェースを介して自らの好みや状況に合った音楽を容易に発見できるシステムの開発に取り組んでいます。 このシステムは、ユーザーが入力する現在の気分や音楽を聞きたい状況といった抽象的なクエリを、大規模言語モデル(LLM)を活用して解釈し、その結果をベクトル形式で表現します。 このベクトルは、接続された音楽データベースとのベクトル検索に基づいたRetrieval-augmented Generation(RAG)の枠組みにより音楽プレイリストを生成するために使用されます。 ベクトル検索部では、音楽の音響的特性に基づくText-to-Music Retrieval、歌詞の意味内容を活用するLyric-to-Music Retrieval、 メタデータに基づくMetadata-based Retrievalなど、音楽の多様な側面を捉える検索技術を開発しており、これらの技術を統合して音楽を検索しています。 ユーザーの漠然としたリクエストを具体的な音楽選択に変換し、パーソナライズされたプレイリストの作成を実現することで、新しい音楽体験の提供を目指しています。
-
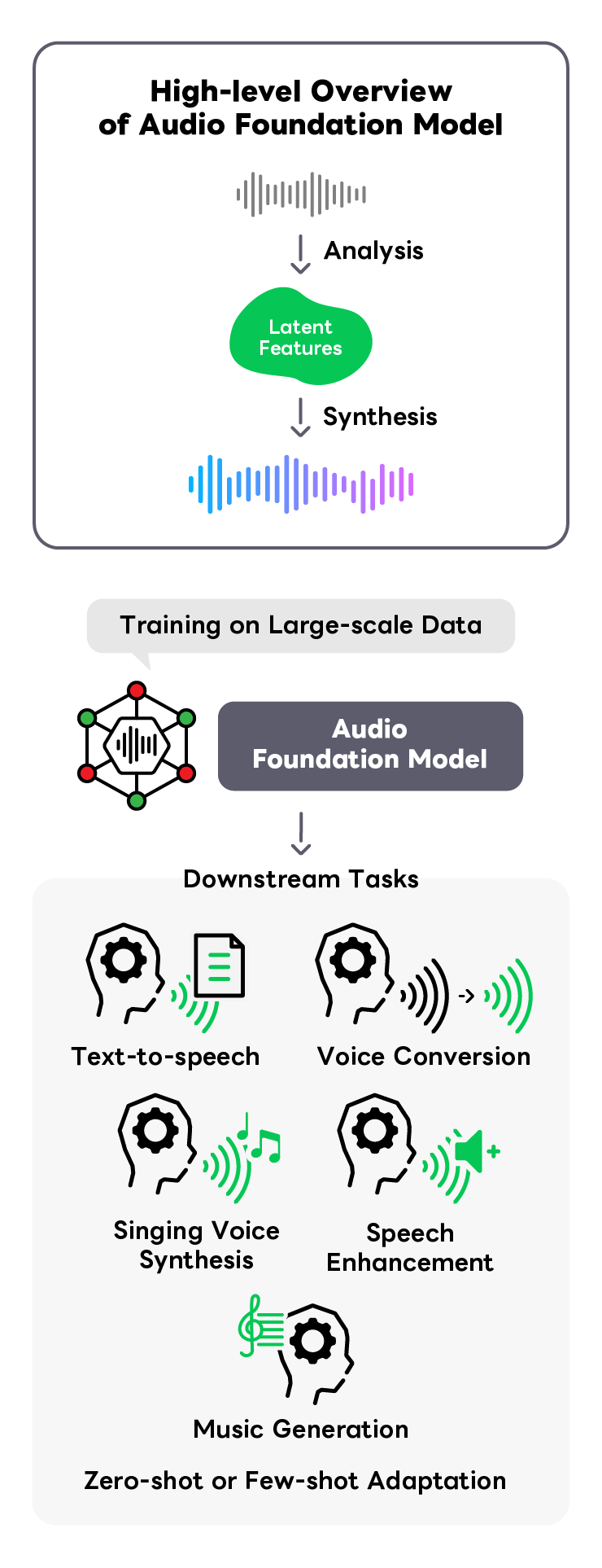
Audio Foundation Model
音声合成、音声変換、音声強調などのさまざまな音声タスクは、個別に特化した機械学習モデルを用いて解決することが一般的でした。 しかし、それぞれに特化したモデルは汎用性に欠け、その応用可能性が限られています。そこで、より汎用的に使える仕組みを実現するため、 われわれは大規模音声データを活用した音声の基盤モデルに関する研究開発をしています。 大規模音声データから汎用的な音声の潜在表現を学習することで、さまざまな下流タスクを少量のデータから実現できるようになります。 音声の基盤モデルの性能向上、マルチモーダル基盤モデルとの統合、下流タスク特化のモデル開発など、多方面から研究を進めています。