Trustworthy AI
信頼できるAIは、AIの安全性、公平性、透明性といった未解決課題の多いチャレンジングな研究分野です。信頼できるAIを実現するため、大規模言語モデルを始めとするAIを、有用で、無害で、正直なものにする方法およびそれらを検証する方法の実現に取り組んでいます。また、AIを活用する際にひとの権利をどのように守るかについても研究しています。

-
LLMのストレステスト
大規模言語モデル (LLM) の有害性や公平性などの倫理的側面を評価するストレステストツールを開発しています。 LLMの脆弱性発見や、有害な出力を抑制するためのSafety Alignmentに活用することを想定しています。

LLMが有する脆弱性や有害な出力をしてしまう傾向をプロアクティブに探索するために、LLMに有害な出力を誘発させるJailbreak法についても研究しています。 一つの事例として、LLMが応答する際の応答開始表現を所定の表現に誘導することで、本来回避するはずの有害な出力を意図的に生成させる手法を開発しました。

-
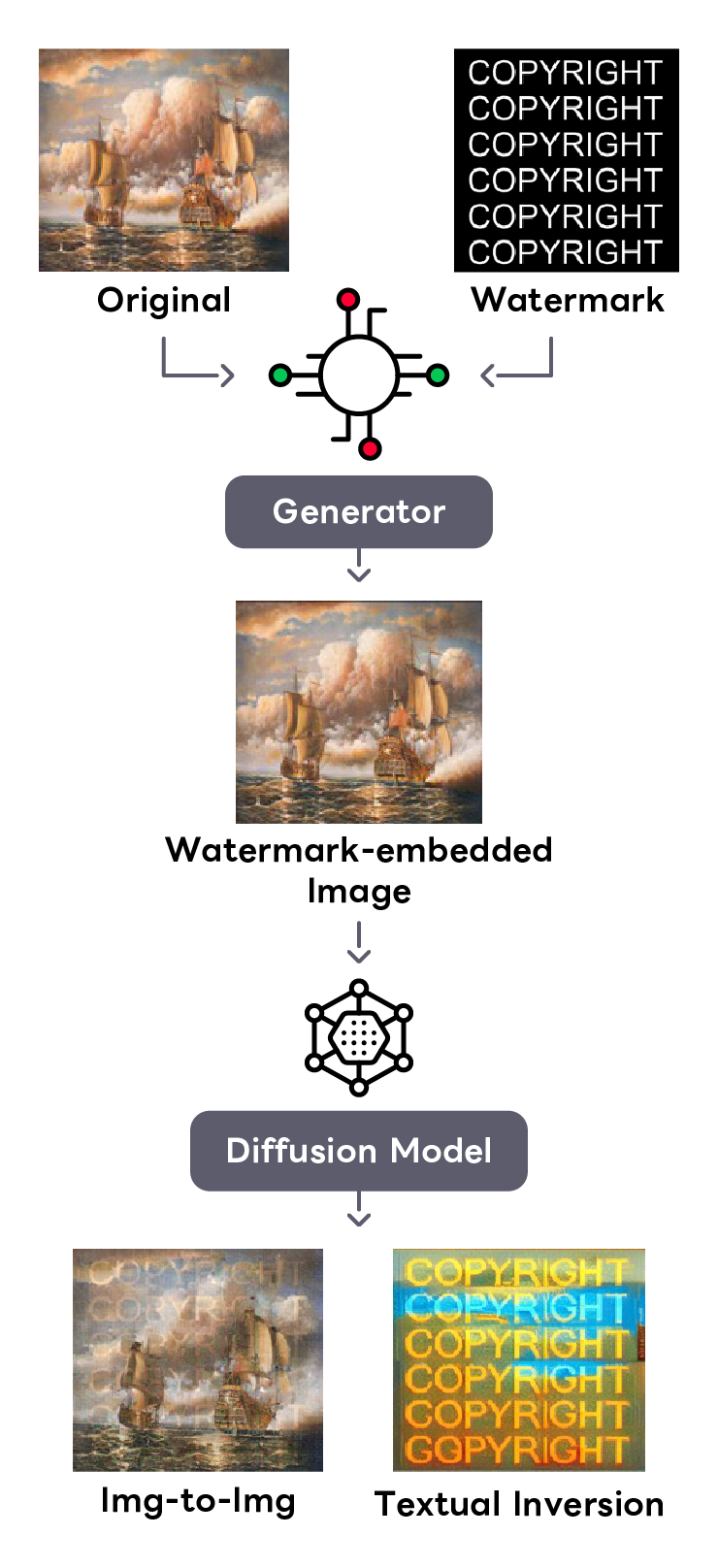
敵対的な透かしによる著作権保護
画像生成AIによって、私たちの著作物である画像を意図せず勝手に改編して利用されてしまうリスクがあります。 このような問題への対策として、Diffusion Modelに入力すると浮き上がる敵対的な「透かし」を開発しました。 意図せず勝手に画像を利用されることを妨害するとともに、透かしによって著作権を主張する一助となればと考えています。